Détection des Violences Domestiques
Pipeline ETL Big Data & NLP qui collecte, nettoie et analyse en continu les commentaires de Twitter et YouTube pour quantifier le phénomène des violences domestiques.
Stack Technique
Big Data
Orchestration
NLP
Backend
Base de données
DataViz
DevOps
Tests
des femmes victimes de violences conjugales
des victimes ne déposent pas plainte
des signaux détectables via les réseaux sociaux
Contexte & Objectifs
Les violences domestiques restent un phénomène massif mais largement sous-déclaré. Les réseaux sociaux constituent paradoxalement un canal d'expression où victimes, témoins et associations partagent quotidiennement témoignages, alertes et signaux faibles. L'enjeu de ce projet est de transformer ce flot non structuré en un signal exploitable, permettant de quantifier le volume, la sévérité, la distribution géographique et l'évolution temporelle du phénomène.
La Problématique
Trois constats motivent ce projet. D'abord, le phénomène est sous-déclaré : environ 85 % des victimes ne franchissent jamais le pas du signalement officiel. Ensuite, près de 60 % des situations à risque laissent pourtant des signaux faibles détectables sur les réseaux sociaux (témoignages, alertes proches, demandes d'aide diffuses). Enfin, le volume et la dispersion de ces messages rendent toute veille manuelle impossible : sans pipeline automatisé, ce capital d'information reste inexploité par les associations et les services de secours.
La Solution
Une architecture distribuée, conteneurisée et orchestrée, exécutable en local comme en production. Apache Airflow orchestre un pipeline ETL en 6 étapes : extraction parallèle via TwitterAPI.io et YouTube Data API v3, stockage brut avec déduplication MongoDB, nettoyage Spark, traitement NLP distribué via UDF PySpark + spaCy (FR & EN), scoring de sévérité pondéré, et persistance des métriques. Les résultats sont exposés par une API FastAPI asynchrone (~12 endpoints) et un dashboard Streamlit interactif avec design glassmorphism. L'ensemble repose sur Docker Compose pour une infrastructure reproductible.
Résultats & Impact
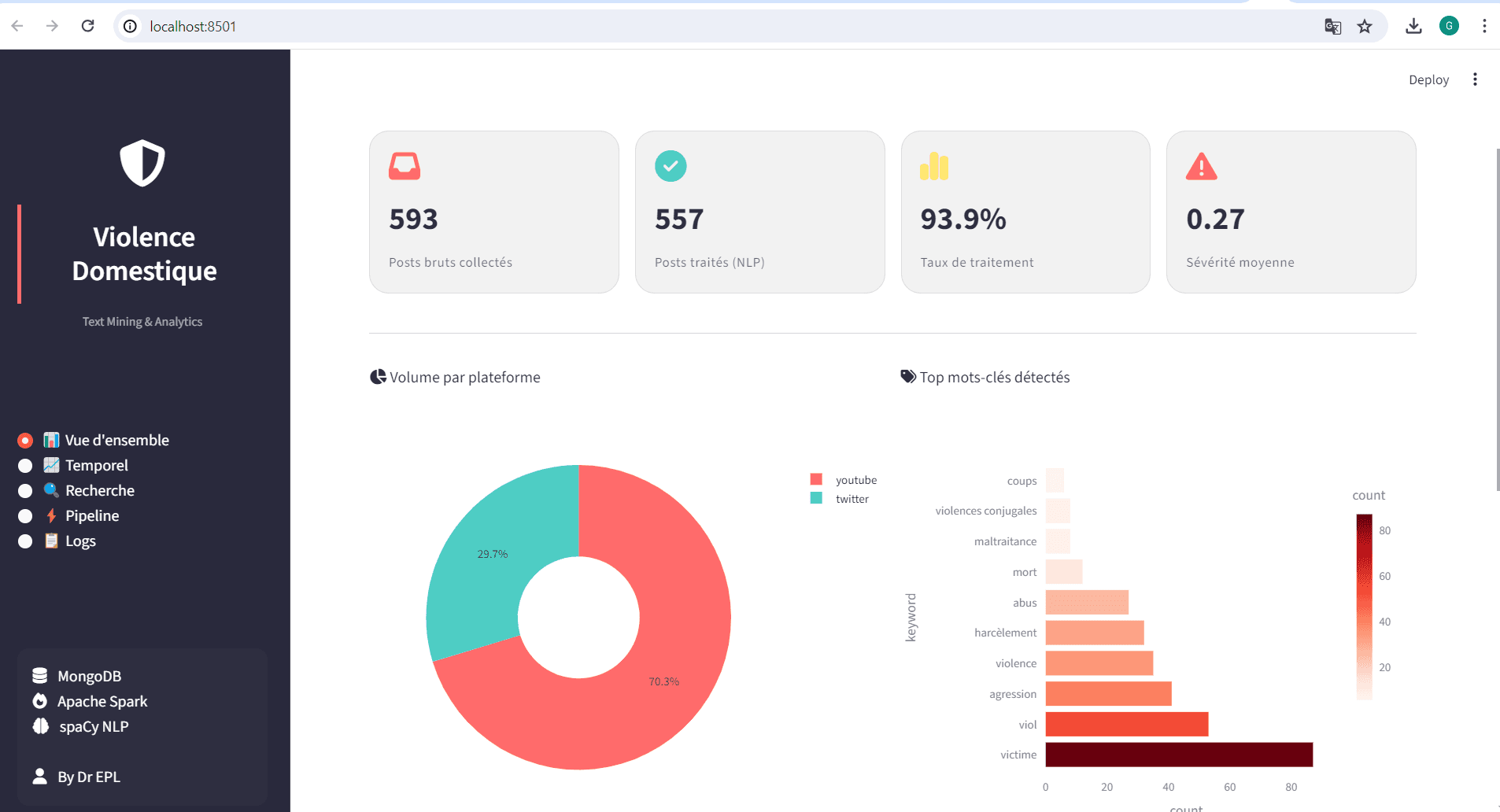
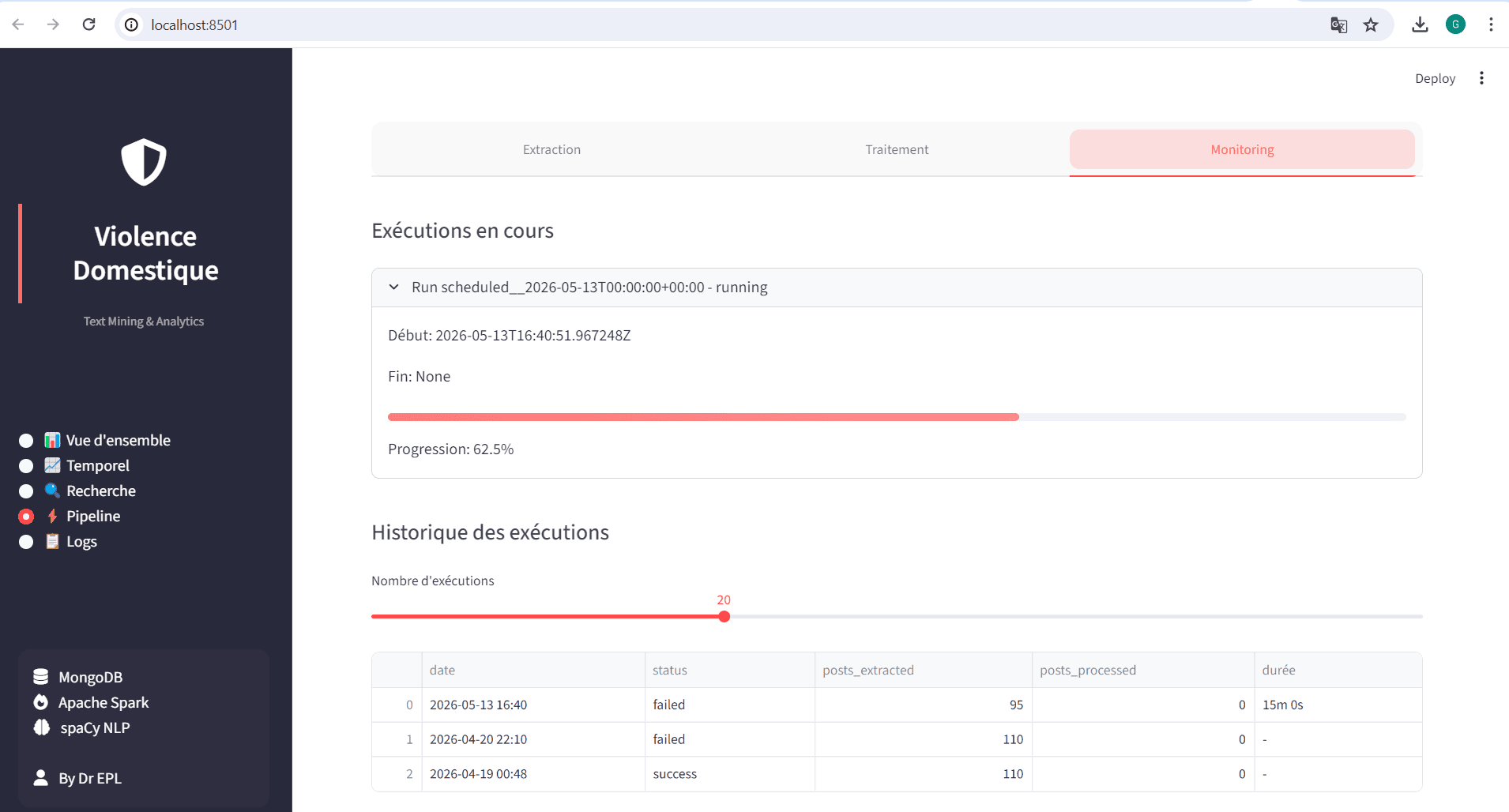
Un système end-to-end fonctionnel, capable d'ingérer plusieurs centaines de publications par run, de les enrichir sémantiquement (tokenisation, lemmatisation, scoring de sévérité 0 à 1) et de fournir des indicateurs exploitables : volume traité, distribution temporelle, cartographie géographique des mentions, histogramme des scores de sévérité, top mots-clés. Le DAG Airflow garantit la résilience (3 retries avec exponential backoff) et la tolérance partielle (si Twitter échoue, YouTube continue). Les logs et métriques du pipeline sont eux-mêmes exploitables via API et dashboard, fournissant une vue de monitoring complète.

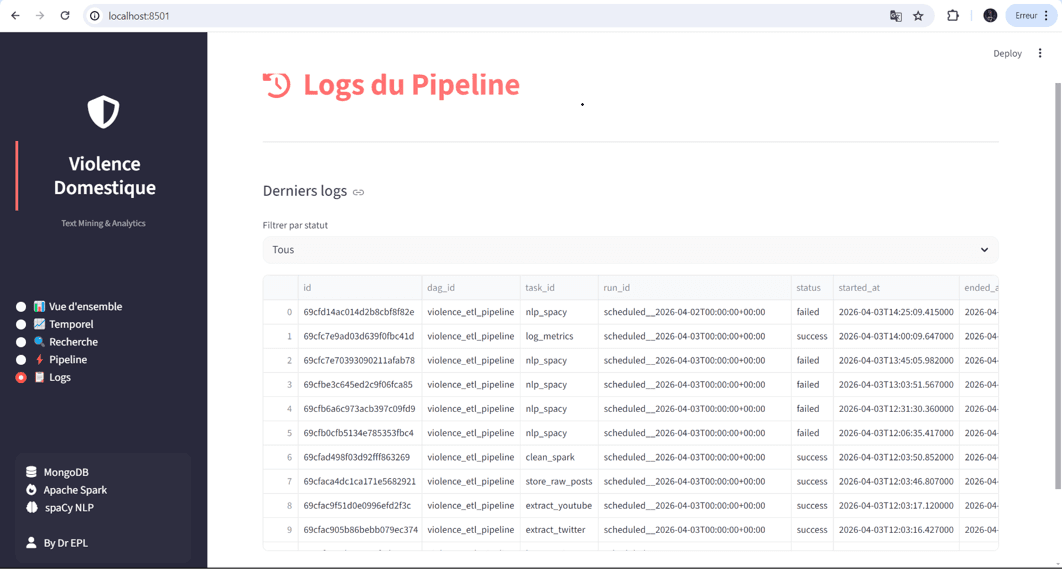
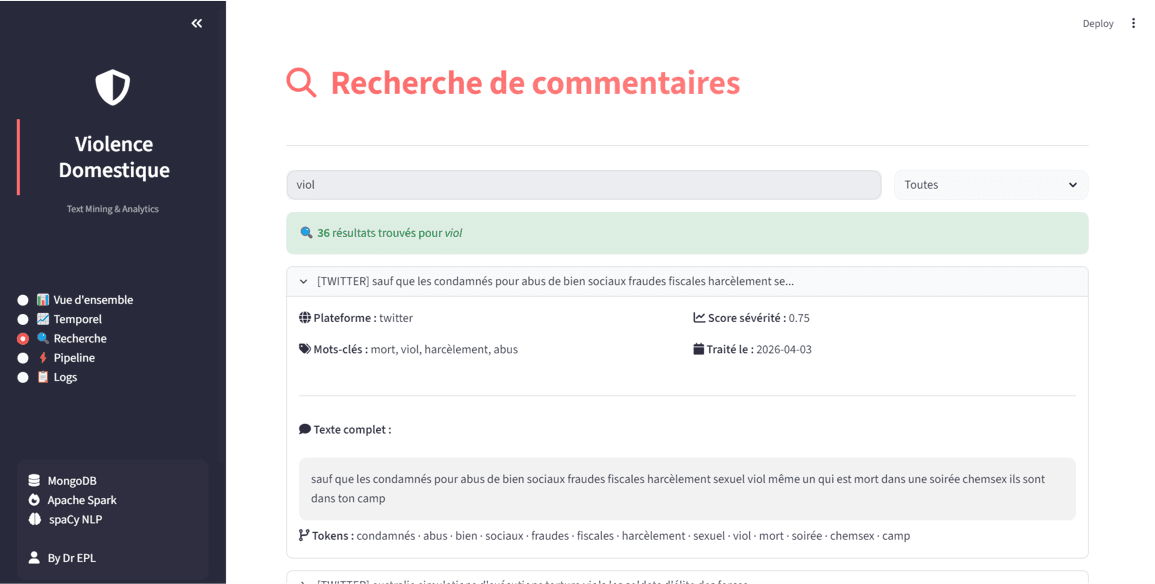
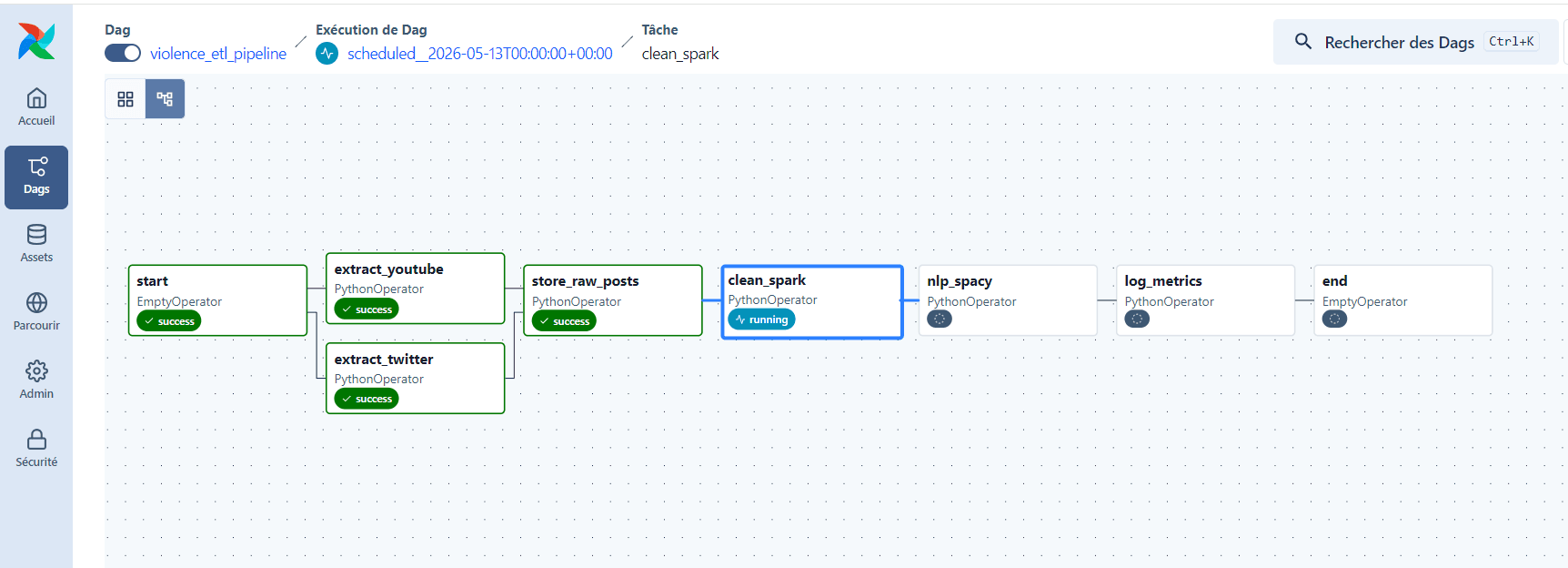
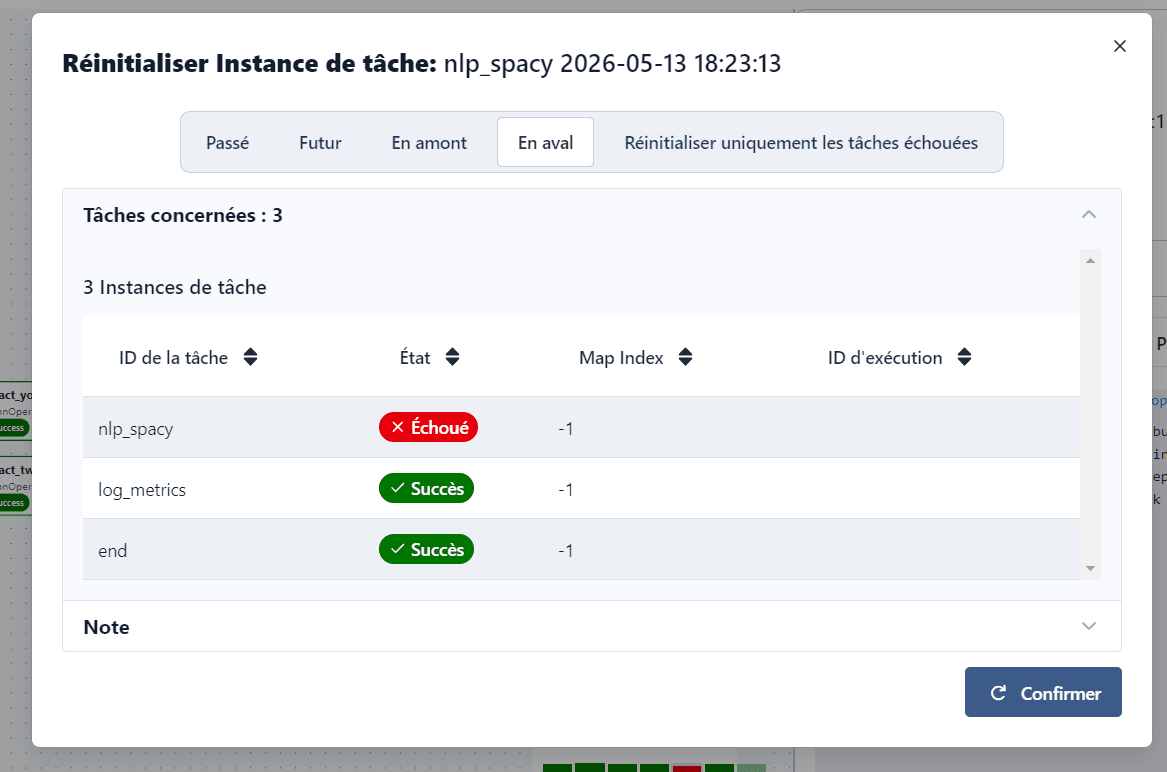
Architecture globale
Vue d'ensemble du pipeline distribué
Pipeline & Étapes
- 1
Extraction parallèle
Deux extracteurs interrogent simultanément Twitter et YouTube sur une liste de mots-clés (violence conjugale, femme battue, harcèlement, etc.).
- 2
Stockage brut
Upsert MongoDB déduplique par (platform, external_id) ; aucune perte, aucun doublon.
- 3
Nettoyage Spark
Suppression des URLs, mentions, emojis, normalisation Unicode, détection de la langue.
- 4
NLP distribué
UDF PySpark + spaCy : tokenisation, lemmatisation, retrait des stopwords, détection des mots-clés de violence.
- 5
Scoring de sévérité
Chaque post reçoit un score entre 0 et 1, calculé à partir d'un dictionnaire pondéré (tuer: 1.0, viol: 0.95, battre: 0.8, …).
- 6
Métriques & logs
Volume traité, taux de transformation et durées sont consignés dans la collection pipeline_metrics.
Adaptations possibles
Projet à vocation démonstrative. L'architecture est réplicable pour tout cas d'usage de text mining sur réseaux sociaux : e-réputation, veille épidémiologique, analyse d'opinion politique, détection de discours haineux.